Human-like learning AI technology
We are a Swiss-based product engineering company that developed a versatile and flexible AI platform combined with appropriate, responsive, and relevant advisory services.
The AI product is based on long-standing practical industry experience and has been developed using the latest technology.
Our AI platform is capable to capture and store information from various data sources, combining multiple AI methods, tools, and services within one unifying platform.
Dydon AI’s technology is a web-service AI suite (supporting cloud and on-premise operation), which combines NLP (Text Analytics), prediction (NeuroFuzzy), central data structuring (multiple taxonomies), and intuitive result presentation (editable dashboard).
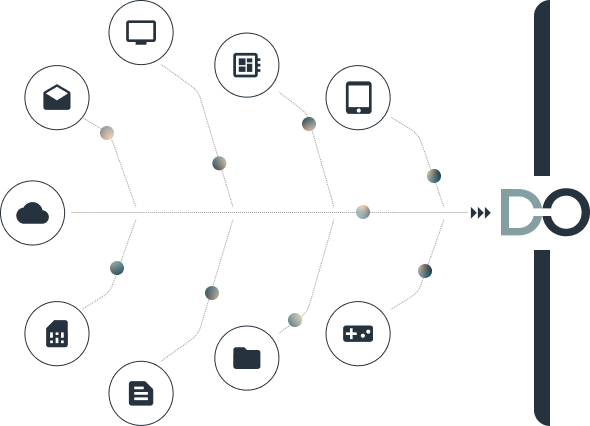
Our platform is able to capture numeric and textual data from various sources and formats. These sources (websites, documents etc.) can be both external and internal data provided by our clients. There is no need for our clients to provide the data in a specific format, we transform it in a way that is processable for us.
A huge number of texts from diverse documents and sources need to be analysed and categorised through a Natural Language Processing stack.
One of the core features of our AI technology are semantic taxonomies for information structuring.
Dydon AG is a Swiss AI company offering a flexible and transparent artificial intelligence platform specialized in Fintech, Insurtech and Medtech solutions

The objective of this process is the generation of analysis and predictive information in the form of ratings, scores, etc. Such results are based on input variables stemming from various data sources.
The platform elaborates KPIs and thresholds based on the previous NPL analysis.

Our prediction engine makes DYDON unique. Dydon AI’s proven Predictive Reasoning methodology combines several soft computing methods (i.e. mathematical formula, point scoring, rule-based aggregation, fuzzy-logic and NeuroFuzzy) to intelligently link and aggregate uploaded or via text analysis extracted input values.
This concept provides full transparency for both the aggregation process and the generated results. Both are important elements to achieve explainable AI results.

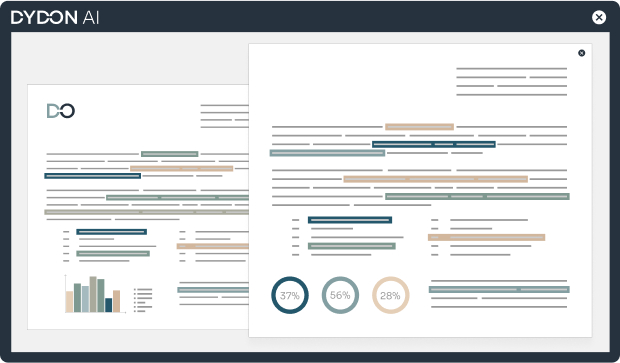
Results are presented in an understandable way. For example, our decision trees allow to drill down to specific results. Our graphics are fully customizable to fit to your needs.

Discover all our solutions
Your ready-to-go AI solution for sustainable finance, compliance, risk management, healthcare services and much more!
